
- Home
- Latest News
![submenu-img]() Meet IIT graduate who designed EVM, worked with Microsoft and Google, he works as…
Meet IIT graduate who designed EVM, worked with Microsoft and Google, he works as…![submenu-img]() Tata Motors planning Rs 8360 crore plant to make luxury cars in India, to set up…
Tata Motors planning Rs 8360 crore plant to make luxury cars in India, to set up…![submenu-img]() Meet man who has bought most expensive property on Bengaluru's 'Billionaire Street', Sudha Murty also...
Meet man who has bought most expensive property on Bengaluru's 'Billionaire Street', Sudha Murty also...![submenu-img]() Israel-Iran news live: Israel conducts air strike in Iran in retaliation to missile attack, says report
Israel-Iran news live: Israel conducts air strike in Iran in retaliation to missile attack, says report![submenu-img]() Neeru Bajwa says Punjabi film industry lacks professionalism: ‘We are not going anywhere until…’
Neeru Bajwa says Punjabi film industry lacks professionalism: ‘We are not going anywhere until…’
- Election 2024
- Webstory
- IPL 2024
- DNA Verified
![submenu-img]() DNA Verified: Is CAA an anti-Muslim law? Centre terms news report as 'misleading'
DNA Verified: Is CAA an anti-Muslim law? Centre terms news report as 'misleading'![submenu-img]() DNA Verified: Lok Sabha Elections 2024 to be held on April 19? Know truth behind viral message
DNA Verified: Lok Sabha Elections 2024 to be held on April 19? Know truth behind viral message![submenu-img]() DNA Verified: Modi govt giving students free laptops under 'One Student One Laptop' scheme? Know truth here
DNA Verified: Modi govt giving students free laptops under 'One Student One Laptop' scheme? Know truth here![submenu-img]() DNA Verified: Shah Rukh Khan denies reports of his role in release of India's naval officers from Qatar
DNA Verified: Shah Rukh Khan denies reports of his role in release of India's naval officers from Qatar![submenu-img]() DNA Verified: Is govt providing Rs 1.6 lakh benefit to girls under PM Ladli Laxmi Yojana? Know truth
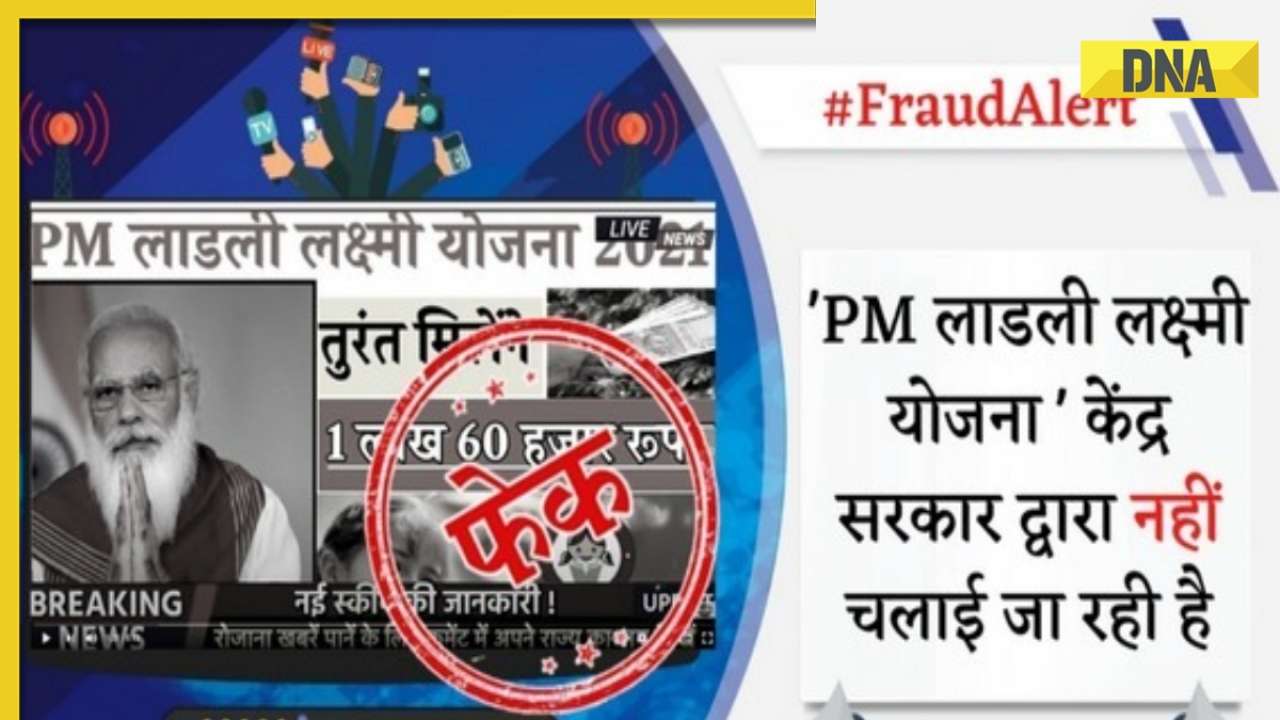
DNA Verified: Is govt providing Rs 1.6 lakh benefit to girls under PM Ladli Laxmi Yojana? Know truth
- DNA Her
- Photos
![submenu-img]() Remember Sana Saeed? SRK's daughter in Kuch Kuch Hota Hai, here's how she looks after 26 years, she's dating..
Remember Sana Saeed? SRK's daughter in Kuch Kuch Hota Hai, here's how she looks after 26 years, she's dating..![submenu-img]() In pics: Rajinikanth, Kamal Haasan, Mani Ratnam, Suriya attend S Shankar's daughter Aishwarya's star-studded wedding
In pics: Rajinikanth, Kamal Haasan, Mani Ratnam, Suriya attend S Shankar's daughter Aishwarya's star-studded wedding![submenu-img]() In pics: Sanya Malhotra attends opening of school for neurodivergent individuals to mark World Autism Month
In pics: Sanya Malhotra attends opening of school for neurodivergent individuals to mark World Autism Month![submenu-img]() Remember Jibraan Khan? Shah Rukh's son in Kabhi Khushi Kabhie Gham, who worked in Brahmastra; here’s how he looks now
Remember Jibraan Khan? Shah Rukh's son in Kabhi Khushi Kabhie Gham, who worked in Brahmastra; here’s how he looks now![submenu-img]() From Bade Miyan Chote Miyan to Aavesham: Indian movies to watch in theatres this weekend
From Bade Miyan Chote Miyan to Aavesham: Indian movies to watch in theatres this weekend
- Explainers
![submenu-img]() DNA Explainer: What is cloud seeding which is blamed for wreaking havoc in Dubai?
DNA Explainer: What is cloud seeding which is blamed for wreaking havoc in Dubai?![submenu-img]() DNA Explainer: What is Israel's Arrow-3 defence system used to intercept Iran's missile attack?
DNA Explainer: What is Israel's Arrow-3 defence system used to intercept Iran's missile attack?![submenu-img]() DNA Explainer: How Iranian projectiles failed to breach iron-clad Israeli air defence
DNA Explainer: How Iranian projectiles failed to breach iron-clad Israeli air defence![submenu-img]() DNA Explainer: What is India's stand amid Iran-Israel conflict?
DNA Explainer: What is India's stand amid Iran-Israel conflict?![submenu-img]() DNA Explainer: Why Iran attacked Israel with hundreds of drones, missiles
DNA Explainer: Why Iran attacked Israel with hundreds of drones, missiles
- Entertainment
![submenu-img]() Neeru Bajwa says Punjabi film industry lacks professionalism: ‘We are not going anywhere until…’
Neeru Bajwa says Punjabi film industry lacks professionalism: ‘We are not going anywhere until…’![submenu-img]() Meet actress who married a CM against her family's wishes, became his second wife, her net worth is..
Meet actress who married a CM against her family's wishes, became his second wife, her net worth is..![submenu-img]() Meet India's richest actress, who started career with two flops, was removed from multiple films, is now worth...
Meet India's richest actress, who started career with two flops, was removed from multiple films, is now worth...![submenu-img]() Meet hit director's niece, who was bullied for 15 years, Bollywood debut flopped, will now star in Rs 200 crore project
Meet hit director's niece, who was bullied for 15 years, Bollywood debut flopped, will now star in Rs 200 crore project![submenu-img]() Abhilash Thapliyal discusses Maidaan, reveals he lost chance to play PK Banerjee in Ajay Devgn's film for this reason
Abhilash Thapliyal discusses Maidaan, reveals he lost chance to play PK Banerjee in Ajay Devgn's film for this reason
- Sports
![submenu-img]() IPL 2024: Ashutosh Sharma's heroics in vain as Mumbai Indians return to winning ways with 9-run victory over PBKS
IPL 2024: Ashutosh Sharma's heroics in vain as Mumbai Indians return to winning ways with 9-run victory over PBKS![submenu-img]() LSG vs CSK, IPL 2024: Predicted playing XI, live streaming details, weather and pitch report
LSG vs CSK, IPL 2024: Predicted playing XI, live streaming details, weather and pitch report![submenu-img]() LSG vs CSK IPL 2024 Dream11 prediction: Fantasy cricket tips for Lucknow Super Giants vs Chennai Super Kings
LSG vs CSK IPL 2024 Dream11 prediction: Fantasy cricket tips for Lucknow Super Giants vs Chennai Super Kings![submenu-img]() PBKS vs MI IPL 2024: Rohit Sharma equals MS Dhoni's massive record, becomes 2nd player to....
PBKS vs MI IPL 2024: Rohit Sharma equals MS Dhoni's massive record, becomes 2nd player to....![submenu-img]() Major setback for CSK as star player ruled out of IPL 2024, replacement announced
Major setback for CSK as star player ruled out of IPL 2024, replacement announced
- Viral News
![submenu-img]() Canada's biggest heist: Two Indian-origin men among six arrested for Rs 1300 crore cash, gold theft
Canada's biggest heist: Two Indian-origin men among six arrested for Rs 1300 crore cash, gold theft![submenu-img]() Donuru Ananya Reddy, who secured AIR 3 in UPSC CSE 2023, calls Virat Kohli her inspiration, says…
Donuru Ananya Reddy, who secured AIR 3 in UPSC CSE 2023, calls Virat Kohli her inspiration, says…![submenu-img]() Nestle getting children addicted to sugar, Cerelac contains 3 grams of sugar per serving in India but not in…
Nestle getting children addicted to sugar, Cerelac contains 3 grams of sugar per serving in India but not in…![submenu-img]() Viral video: Woman enters crowded Delhi bus wearing bikini, makes obscene gesture at passenger, watch
Viral video: Woman enters crowded Delhi bus wearing bikini, makes obscene gesture at passenger, watch![submenu-img]() This Swiss Alps wedding outshine Mukesh Ambani's son Anant Ambani's Jamnagar pre-wedding gala
This Swiss Alps wedding outshine Mukesh Ambani's son Anant Ambani's Jamnagar pre-wedding gala









































)
)
)
)
)
)